爬取百度任意类型的图片
本文共 1640 字,大约阅读时间需要 5 分钟。
该代码用到了selenium库和request库:
写的思想如下: 1.先用selenium模仿人在 中,对想要的图片进行搜索; 2.分析页面的源代码,其实这些图片应该不是百度自己上传的,按f12调试工具,找到第一张图片的连接:
2.分析页面的源代码,其实这些图片应该不是百度自己上传的,按f12调试工具,找到第一张图片的连接: 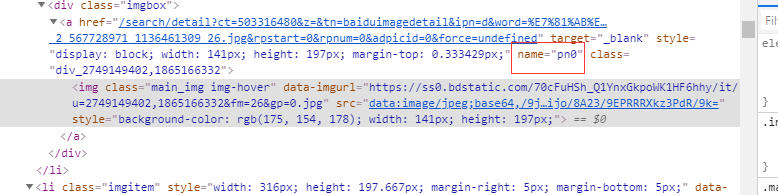
图片img标签被超链接a标签所包裹,意思就是你点击图片,其实跳转的就是a标签href那个地址,这一点很关键!!!!!
再就是找一个规律,怎么才可以定位出第一张图片,注意要有普遍性,用XPath肯定是不行的,因为搜索其他图片可能值就会变,而我们的代码要有普遍性。经过观察,我发现a标签的name=pn0 就是个很好的定位标准,无论搜索什么,第一张图片的name都为pn0 3.让浏览器仿照人点击这张图片,也就是访问a标签那个href 然后继续分析该页面的源码: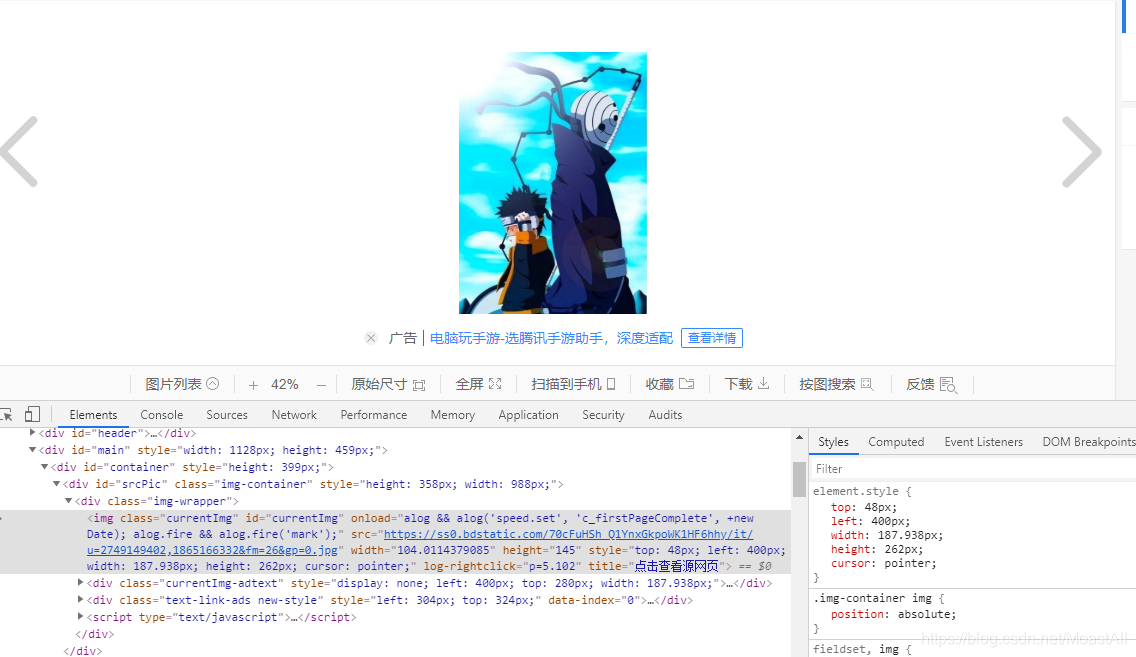
 人就是点击右边那个按钮切换到下一张的,可以直接定位该按钮,让selenium模仿人进行点击,然后重复上面的下载步骤即可连续下载!
人就是点击右边那个按钮切换到下一张的,可以直接定位该按钮,让selenium模仿人进行点击,然后重复上面的下载步骤即可连续下载! 下面就是所有的源码
from selenium import webdriverimport requestsdef looking(mubiao): chrome_driver = 'E:\\chromedriver_win32\\chromedriver.exe' driver = webdriver.Chrome(executable_path = chrome_driver) driver.get('https://image.baidu.com/') driver.find_element_by_id('kw').send_keys(mubiao) driver.find_element_by_class_name('s_search').click() href = driver.find_element_by_name("pn0").get_attribute('href') print(href) return href driver.close()def download(url,n): chrome_driver = 'E:\\chromedriver_win32\\chromedriver.exe' driver = webdriver.Chrome(executable_path = chrome_driver) driver.get(url) for i in range(n): ret = driver.find_element_by_class_name("currentImg").get_attribute("src") response = requests.get(ret) with open(r'E:\Photo\%s.jpg' % (i+1),'wb') as f: print("第",i+1,"张图片下载完毕!!!") f.write(response.content) driver.find_element_by_xpath('//*[@id="container"]/span[2]/span').click() driver.close()if __name__== "__main__": mubiao = input("请输入要下载的图片类型:") n = int(input("请输入下载数量:")) url = looking(mubiao) download(url,n) 下载效果图:
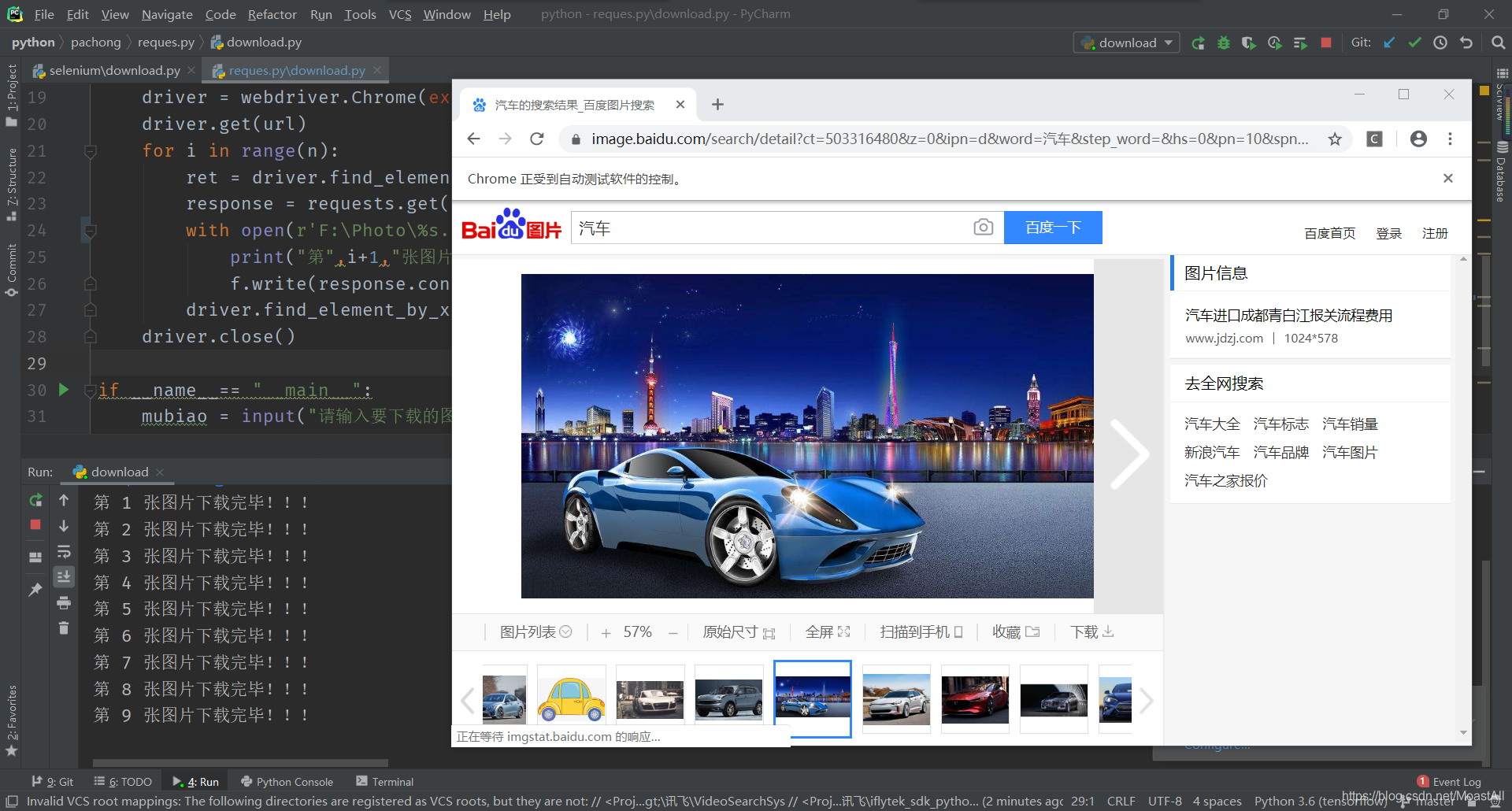
转载地址:http://wfhe.baihongyu.com/
你可能感兴趣的文章
mysql 的存储引擎介绍
查看>>
MySQL 的存储引擎有哪些?为什么常用InnoDB?
查看>>
mysql 索引
查看>>
MySQL 索引失效的 15 种场景!
查看>>
MySQL 索引深入解析及优化策略
查看>>
MySQL 索引的面试题总结
查看>>
mysql 索引类型以及创建
查看>>
MySQL 索引连环问题,你能答对几个?
查看>>
Mysql 索引问题集锦
查看>>
Mysql 纵表转换为横表
查看>>
mysql 编译安装 window篇
查看>>
mysql 网络目录_联机目录数据库
查看>>
MySQL 聚簇索引&&二级索引&&辅助索引
查看>>
Mysql 脏页 脏读 脏数据
查看>>
mysql 自增id和UUID做主键性能分析,及最优方案
查看>>
Mysql 自定义函数
查看>>
mysql 行转列 列转行
查看>>
Mysql 表分区
查看>>
mysql 表的操作
查看>>
mysql 视图,视图更新删除
查看>>